
使用语音识别功能之前,先按照说明书安装百度语音输入软件。在浏览器中输入voicem380底部的软件下载链接,就可以直接进入软件下载界面了,清晰简单,自行选择win版/mac版,跟着界面提示一部一部操作就ok。中间绑定手机/邮箱账号,接收验证码,输入voicem380底部的码。安装流程就结束了,让我们来试试神奇的语音识别~先试了一下普通话模式,据官方说,每分钟可听写约400字,准确率高达98%。特意找了一段听起来十分晦涩、拗口的话来测试,先清点voicem380的语音识别键。此时电脑右下角出现小弹框,进入语音接收阶段。以正常语速随便读了一下,转化效果非常好,实现零误差;而且对于智能语音识别中的“智能”也有了很好的诠释,如动图,有些人名、专有名词不能在一时间正确输出,但会随着语音的不断输入,不断修正、调整前面的内容;输入结束后,可以再次轻点voicem380的语音识别键,进入“识别”阶段,个人感觉,更像是对于刚刚输出的内容进行后的整合;如果刚刚的输出有出现标点错乱、错别字的现象,会在这个识别阶段,统一调整,终整合后输出的内容,正确率十分ok。接着试了一下中译英模式和英译中模式,整体操作和普通话模式一致。虽然涉及了不同语种之间的翻译转化。语音识别,通常称为自动语音识别。贵州语音识别在线

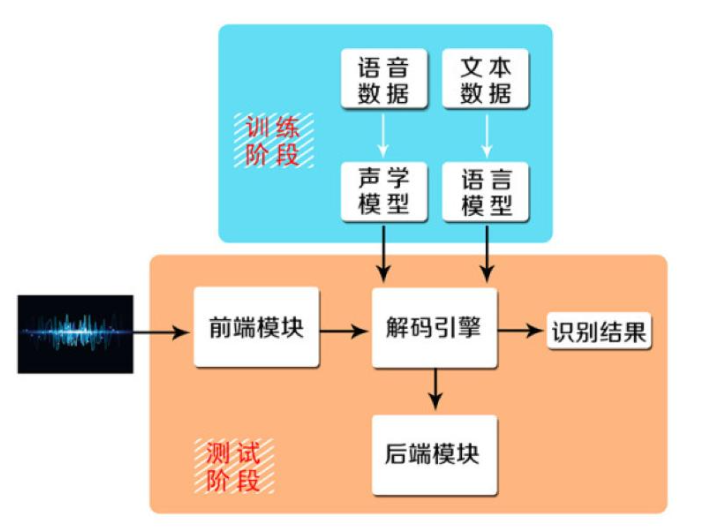
训练通常来讲都是离线完成的,将海量的未知语音通过话筒变成信号之后加在识别系统的输入端,经过处理后再根据语音特点建立模型,对输入的信号进行分析,并提取信号中的特征,在此基础上建立语音识别所需的模板。识别则通常是在线完成的,对用户实时语音进行自动识别。这个过程又基本可以分为“前端”和“后端”两个模块。前端主要的作用就是进行端点检测、降噪、特征提取等。后端的主要作用是利用训练好的“声音模型”和“语音模型”对用户的语音特征向量进行统计模式识别,得到其中包含的文字信息。语音识别技术的应用语音识别技术有着应用领域和市场前景。在语音输入控制系统中,它使得人们可以甩掉键盘,通过识别语音中的要求、请求、命令或询问来作出正确的响应,这样既可以克服人工键盘输入速度慢,极易出差错的缺点,又有利于缩短系统的反应时间,使人机交流变得简便易行,比如用于声控语音拨号系统、声控智能玩具、智能家电等领域。在智能对话查询系统中,人们通过语音命令,可以方便地从远端的数据库系统中查询与提取有关信息,享受自然、友好的数据库检索服务,例如信息网络查询、医疗服务、银行服务等。语音识别技术还可以应用于自动口语翻译。黑龙江语音识别器多人语音识别及离线语音识别也是当前需要重点解决的问题。
并能产生兴趣投身于这个行业。语音识别的技术历程现代语音识别可以追溯到1952年,davis等人研制了世界上个能识别10个英文数字发音的实验系统,从此正式开启了语音识别的进程。语音识别发展到已经有70多年,但从技术方向上可以大体分为三个阶段。下图是从1993年到2017年在switchboard上语音识别率的进展情况,从图中也可以看出1993年到2009年,语音识别一直处于gmm-hmm时代,语音识别率提升缓慢,尤其是2000年到2009年语音识别率基本处于停滞状态;2009年随着深度学习技术,特别是dnn的兴起,语音识别框架变为dnn-hmm,语音识别进入了dnn时代,语音识别精细率得到了提升;2015年以后,由于“端到端”技术兴起,语音识别进入了百花齐放时代,语音界都在训练更深、更复杂的网络,同时利用端到端技术进一步大幅提升了语音识别的性能,直到2017年微软在swichboard上达到词错误率,从而让语音识别的准确性超越了人类,当然这是在一定限定条件下的实验结果,还不具有普遍代表性。gmm-hmm时代70年代,语音识别主要集中在小词汇量、孤立词识别方面,使用的方法也主要是简单的模板匹配方法,即首先提取语音信号的特征构建参数模板,然后将测试语音与参考模板参数进行一一比较和匹配。
语音识别自半个世纪前诞生以来,一直处于不温不火的状态,直到2009年深度学习技术的长足发展才使得语音识别的精度提高,虽然还无法进行无限制领域、无限制人群的应用,但也在大多数场景中提供了一种便利高效的沟通方式。本篇文章将从技术和产业两个角度来回顾一下语音识别发展的历程和现状,并分析一些未来趋势,希望能帮助更多年轻技术人员了解语音行业,并能产生兴趣投身于这个行业。语音识别,通常称为自动语音识别,英文是automaticspeechrecognition,缩写为asr,主要是将人类语音中的词汇内容转换为计算机可读的输入,一般都是可以理解的文本内容,也有可能是二进制编码或者字符序列。但是,我们一般理解的语音识别其实都是狭义的语音转文字的过程,简称语音转文本识别(speechtotext,stt)更合适,这样就能与语音合成(texttospeech,tts)对应起来。语音识别是一项融合多学科知识的前沿技术,覆盖了数学与统计学、声学与语言学、计算机与人工智能等基础学科和前沿学科,是人机自然交互技术中的关键环节。但是,语音识别自诞生以来的半个多世纪,一直没有在实际应用过程得到普遍认可,一方面这与语音识别的技术缺陷有关,其识别精度和速度都达不到实际应用的要求。
由于语音交互提供了更自然、更便利、更高效的沟通形式,语音识别必定将成为未来主要的人机互动接口之一。
第三个关键点正是amazonecho的出现,纯粹从语音识别和自然语言理解的技术乃至功能的视角看这款产品,相对于siri等并未有什么本质性改变,变化只是把近场语音交互变成了远场语音交互。echo正式面世于2015年6月,到2017年销量已经超过千万,同时在echo上扮演类似siri角色的alexa渐成生态,其后台的第三方技能已经突破10000项。借助落地时从近场到远场的突破,亚马逊一举从这个赛道的落后者变为行业者。但自从远场语音技术规模落地以后,语音识别领域的产业竞争已经开始从研发转为应用。研发比的是标准环境下纯粹的算法谁更有优势,而应用比较的是在真实场景下谁的技术更能产生优异的用户体验,而一旦比拼真实场景下的体验,语音识别便失去存在的价值,更多作为产品体验的一个环节而存在。所以到2019年,语音识别似乎进入了一个相对平静期,全球产业界的主要参与者们,包括亚马逊、谷歌、微软、苹果、百度、科大讯飞、阿里、腾讯、云知声、思必驰、声智等公司,在一路狂奔过后纷纷开始反思自己的定位和下一步的打法。语音赛道里的标志产品——智能音箱,以一种的姿态出现在大众面前。2016年以前。更重要的是体现在世界范围内的各行各业在设计和部署语音识别系统时均采用了各种深度学习方法。广州自主可控语音识别介绍
一些语音识别系统需要“训练”(也称为“注册”),其中个体说话者将文本或孤立的词汇读入系统。贵州语音识别在线
应用背景随着信息时代的到来,语音技术、无纸化技术发展迅速,但是基于会议办公的应用场景,大部分企业以上技术应用都不够广,会议办公仍存在会议记录强度高、出稿准确率低,会议工作人员压力大等问题。为解决上述问题,智能语音识别编译管理系统应运而生。智能语音识别编译管理系统的主要功能是会议交流场景下语音实时转文字,解决了人工记录会议记要易造成信息偏差、整理工作量大、重要会议信息得不到体系化管控、会议发言内容共享不全等问题,提升语音技术在会议中的应用水平,切实提升会议的工作效率。实现功能智能语音识别编译管理系统对会议信息进行管理,实现实时(历史)会议语音转写和在线编辑;实现角色分离、自动分段、关键词优化、禁忌词屏蔽、语气词过滤;实现全文检索、重点功能标记、按句回听;实现展板设置、导出成稿、实时上屏等功能。技术特点语音转文字准确率高。系统中文转写准确率平均可达95%,实时语音转写效率能够达到≤200毫秒,能够实现所听即所见的视觉体验。系统能够结合前后文智能进行语句顺滑、智能语义分段,语音转写过程中也能够直接对转写的文本进行编辑,编辑完成后即可出稿。会议内容记录更完整。系统可实现对全部发言内容的记录。贵州语音识别在线